Testbed
Testbed
At the centre of EVOLVE lies an advanced HPC-enabled testbed that is able to process unprecedented dataset sizes and to deal with heavy computation, while allowing shared, secure, and easy deployment, access, and use.
The EVOLVE testbed is a concrete step in bringing together features from the Big Data, HPC, and Cloud worlds, directly contributing to their convergence.
Data
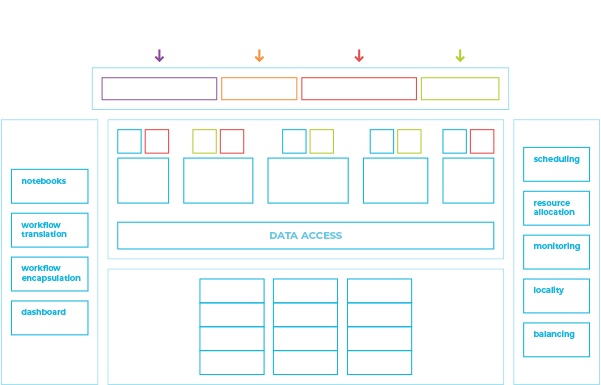
As shown above, EVOLVE’s tested is based on:
Advanced Computing Platform
The main aspects of EVOLVE’s hardware platform are:
Scale
The system intends to allow using multiple racks for each workflow, each rack encompassing a few thousand processors and 10s of TB of memory. Individual workflow access to resources will be limited by technology constraints, as is typically the case in HPC environments.
Large Memories
System nodes are aimed to include large amounts of memory (several 10s GB/core), which is an important aspect for certain types of data processing. EVOLVE’s platform is making use of large-memory technology to enable large dataset processing that otherwise incur significant overheads.
Accelerated Processing
Each server is aimed to include accelerators, FPGAs and GPUs that have the potential to dramatically increase the efficiency and density of processing. The hardware platform of EVOLE constitutes one of the main platforms available today with such capabilities and is projected to play an important role in the future for data processing and high-performance data analytics.
Fast Interconnect
System nodes are being interconnected with an RDMA-type interconnect that offers low latency and high bandwidth for demanding computation.
Storage Subsystem Architecture
In EVOLVE the storage is envisioned as a tiered architecture. Depending on the workload characteristics a distinct hardware component will be improved and tuned in the process of reaching the target performance. The storage subsystem uses two important technologies:
- A shared Infinite Memory Engine (IME)
- Fast, local NVMe storage devices
Additionally, EVOLVE’s storage subsystem is using data protection, data integrity, and capacity optimization techniques resulting in the use of state-of-the-art technologies for storing and accessing data. To fully support widely-used best-practice big-data tools, EVOLVE is offering HDFS, a de-facto standard in the BD ecosystem, as the basic storage-access API.
Versatile Software Stack
EVOLVE is using end-to-end workflows that express full data-processing pipelines rather than individual isolated data-processing stages. EVOLVE workflows include data ingest from external sources, such as domain specific data repositories, archival storage, as well as up-to-date real-time data.
EVOLVE’s workflows aim to:
- Allow users to specify data sources and computation components in a manner consistent with end-to-end business. Individual workflow access to resources will be limited by technology constraints, as is typically the case in HPC environments.
- Express various types of data transformations prior to processing.
- Allow users to specify the required visualisation and also to extract and save data for later use or other purposes.
- Seamlessly integrate scalable visualization to its testbed and support it as first-class citizen in workflows.
- Express in workflows HPC stages, using domain specific libraries or HPC-kernels that have been optimized for specific functions and purposes.
To realize workflows, EVOLVE is providing a versatile software stack that employs existing data processing engines that have proven flexibility and breadth of applicability.
Safety & Ease of Deployment, Access & Use
EVOLVE aims to provide ease of access, deployment, and use of the testbed. EVOLVE will provide shared access to the testbed for improving productivity and TCO, by embedding data encryption in the testbed, combined with erasure coding for integrity and capacity optimization. This approach achieves three important goals related data privacy and integrity:
Privacy
It allows the testbed to be shared without concerns that other users will be able to have access to data.
Integrity
It allows each application to check if data has been tampered with or modified in an undesired manner.
Capacity
It allows each application to use significantly larger datasets, taking advantage of the performance of fast devices present in the testbed, effectively increasing multiple times the system capacity (reducing TCO).